Investing in “AI” or, more realistically, Machine Learning is the fashionable thing to do these days (in addition to investing in SPAC’s, NFT’s, etc.). But does your fledgling start-up really need a Machine Learning solution? Vinay Muttineni MBA2021 helped build scalable machine-learning pipelines and products at eBay and Microsoft. In the second post of a three-part series, he highlights the different stages of the model building process.

In this post, I explore the seven key stages of a model building process. Not all stages are created equal and some might take significantly more time and resources than others. I’ll highlight these and other idiosyncrasies as I step through each stage. If you want to follow along on a sample dataset, here are (Full version, Simplified version, Face Recognition) a few simple ML notebooks I use in my workshops.
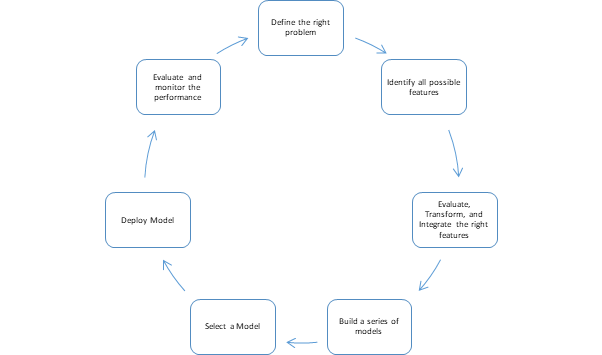
(St)age 1: Define the RIGHT problem
I wrote quite a bit about this in the first part of the blog series so I’ll refrain from repeating myself and boring you with the details but ensure you have answers to these three questions.
- What are you solving for?
- How is ML going to add value?
- How will you measure success?
(St)age 2: Identify all possible features
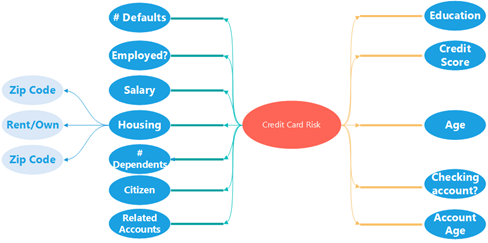
- A “feature” is a variable that can help predict the final outcome. Ex: If you are building a credit risk model, the number of prior late payments could be a useful feature.
- Talk to your teammates, your partner teams, designers, PMs…
- Essentially, anyone who knows anything about your product.
- Brainstorm feature ideas. Remember, no idea is too stupid.
- Create a mind map of possible features.
- Do NOT discard any features in this stage.
Useful Tech in this phase
- Lucid Charts, Miro, Visio for mind-maps, Whiteboard!.
A simple mind-map
(St)age 3: Evaluate, Transform, and Integrate the right features
This is easily the most cumbersome step in the whole process. Feature engineering might end up taking 70% (if not more) of the end-to-end process time.
As a first step, evaluate your feature and platform choices. Some of the questions that are worth considering at this stage include:
- How many of the features described in the previous stage are you going to consider for the first model?
- Remember to always start small. Don’t go about building a 1,500 rich feature dataset right away.
- How easy is it to get these features both for training and in production?
- It might be worthwhile to cull some features at this stage if the value add is low compared to the effort required to build them.
- What data platform is best suited for this task?
- The answer to this depends on the size of your feature set and, also, on the availability of the intended data platform.
Transform & Integrate:
- Invest some time in understanding your data. Look at data summary stats (ex: Mean, median, mean absolute deviation, etc.). Visualizations might help.
- Transform your dataset:
- Convert categorical variables into numerical ones if needed. Strategies include replacing text with numbers, creating multiple dummy variables, using frequency distributions, etc.
- Null value analysis: Devise a null value replacement strategy. Commonly used techniques include ignoring the records with a missing value, replacing them with a constant/statistical measure (ex: Median), building a model to generate the most probable values.
- Data Normalization: You don’t want a variable with a large domain to have an outsized impact. Commonly used method: Subtract the mean and divide by the standard deviation.
- Data Redundancy & Correlation analysis: Remove redundant/correlated features.
- Unique Value Analysis: In general, a feature with low variability has less effect on the model. Consider removing such features.
- Dimensionality Reduction: In addition to removing any redundant features, try algorithmic means to reduce the dimensionality. Use PCA/ICA to achieve this.
- Integrate: Combine the data collected from multiple sources into a single datastore.
Useful Tech
- Apache Spark (DataBricks) for data transformation jobs on “Big Data”.
- Python for running data summarization tasks on smaller datasets.
- Power BI, Python, custom-built websites for data visualization.
(St)age 4: Build a model/series of models
- Divide your data into
- Training Dataset: Train your model(s) on this data.
- Validation Dataset: Tune your model by changing the various hyperparameters based on the model performance on this dataset.
- Test Dataset: Test your model performance on this dataset and report performance metrics.
- Choose an algorithm and build a model to fit your data.
- Remember – Train a model to fit your data. Do not fit your data to a model.
- Or pick a bunch of algorithms and train a series of models.
- Use ensemble or boosted models to reduce variance.
Useful Tech
- Python/R/Matlab.
- Python Jupyter Notebooks for easy sharing of code.
- Apache Spark on Hadoop for distributed training.
- GPU clusters can help speed up training for a few algorithms.
- Cloud-based Visual ML solutions like Azure ML Studio for code-free Machine Learning.
- Auto ML solutions like “Azure Automated Machine Learning” for a completely automated solution.
(St)age 5: Select a Model
- Pick a model or an ensemble of models.
- Consider the model’s performance on the Validation set to make this decision.
- Consider different metrics – Precision-Recall Score, ROC, etc.
- Present Visualizations to convince key stakeholders about the usefulness of the product. Remember success in this stage is as much about convincing your project sponsors as it is about building a “perfect” model.
(St)age 6: Deploy the Model
- Deploy the model to production – usually done by embedding it in a web service.
- Consider a Lambda Architecture to deliver both near-real-time and aggregated data to your service.
(St)age 7: Evaluate and Monitor the Performance
- Infuse enough telemetry into your service(s).
- Build charts to measure your model performance over time.
- Use this data to refine your model.
Finally, remember to iterate on your model. Go back to step 1 and use the additional data and insights gathered in production to train better models.
This is part 2 of a three-part blog series. In the first edition, we go through some questions that help you decide if you really need ML. In the final edition, I will leave you with tips around running an ML project.
If you liked this, you might like Five truths about algorithms you should know.
About the author: Vinay Muttineni, an MBA student, has over 6 years of experience in Silicon Valley. There he helped build scalable machine-learning pipelines and products at eBay and Microsoft. He has a Masters in Computer Science from the University of Illinois at Urbana-Champaign. Now he is completing an MBA at London Business School. He has also worked in product roles at nPlan and Ori Biotech.
Previously, he volunteered at various high schools in the Bay Area teaching Computer Science. Currently, he is mentoring students from non-target CS colleges through the Mentors in Tech program.